
I’m a second-year S.M. student in Data Science at Harvard University, advised by Prof. Yogesh Rathi from Mass General Brigham and Prof. Todd Zickler from Harvard SEAS. Previously, I earned dual B.S. degrees in Computer Science and Data Science from the University of Wisconsin–Madison, where I was fortunate to be advised by Prof. Vikas Singh.
My research lies at the intersection of computer vision, medical imaging, and signal processing — focusing on integrating geometric, temporal, and physical constraints into deep learning frameworks for interpretable and domain-adaptive perception in medical and broader visual systems.
I am also passionate about teaching and have served as a Teaching Fellow (Teaching Assistant) for multiple courses at Harvard and UW-Madison. You can find more details about my teaching experience here.
Research Interests
My research interests include:
- Computer Vision
- Medica Imaging
- 3D vision and Scene Understanding
Projects
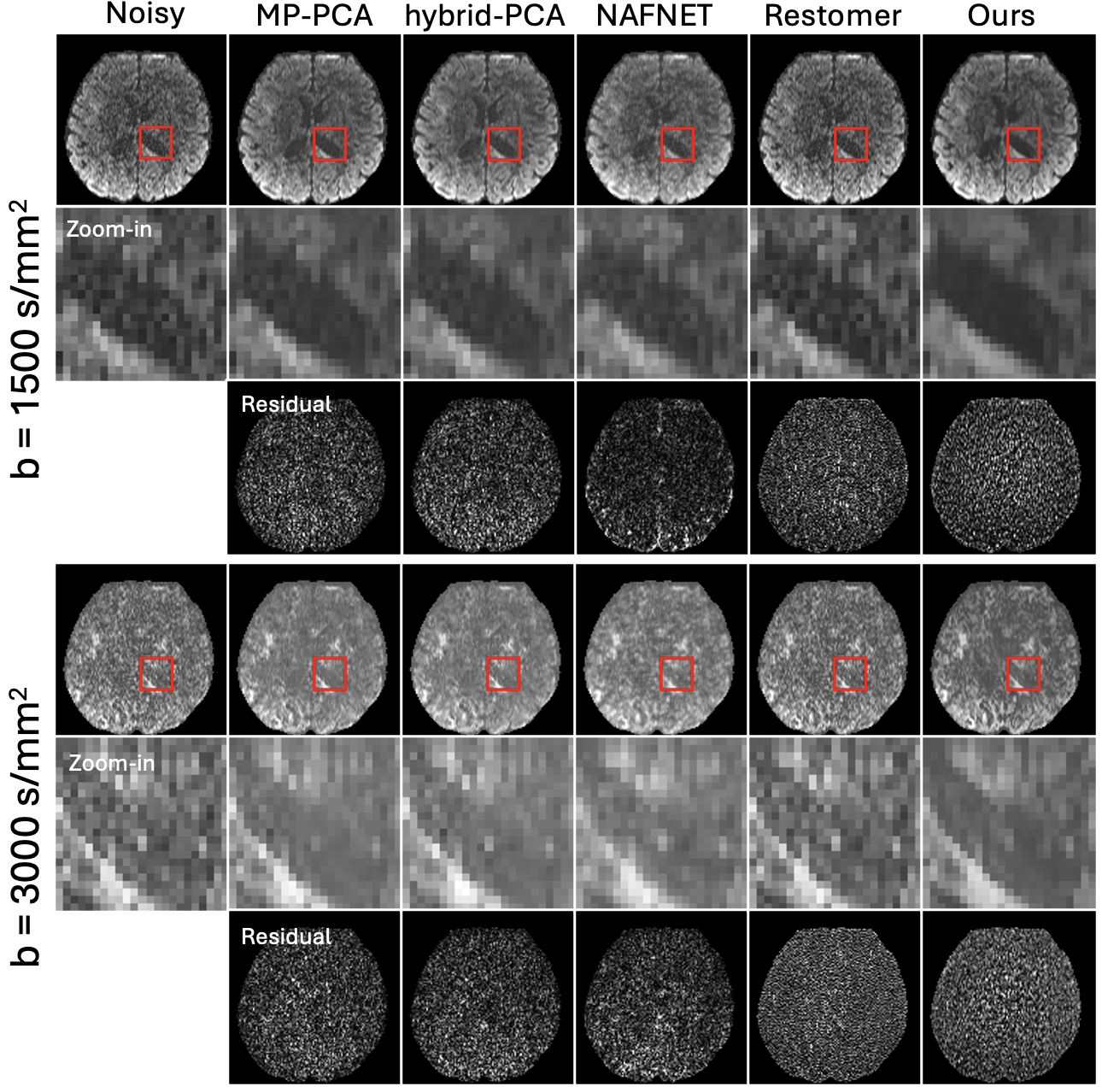
Scanner-Adaptive Coil-Level Denoising for Diffusion MRI Using Explicit Noise Priors
Linbo Tang, Qiang Liu, Lipeng Ning, Yogesh Rathi
In submission to ISBI 2026
Developed a scanner-adaptive, coil-level denoising framework that conditions on measured noise statistics for robust performance across scanners and protocols. The method achieved up to a 23% reduction in residual noise compared to the next best-performing approach on in-vivo multi-coil diffusion MRI data.
project page / arXiv / code
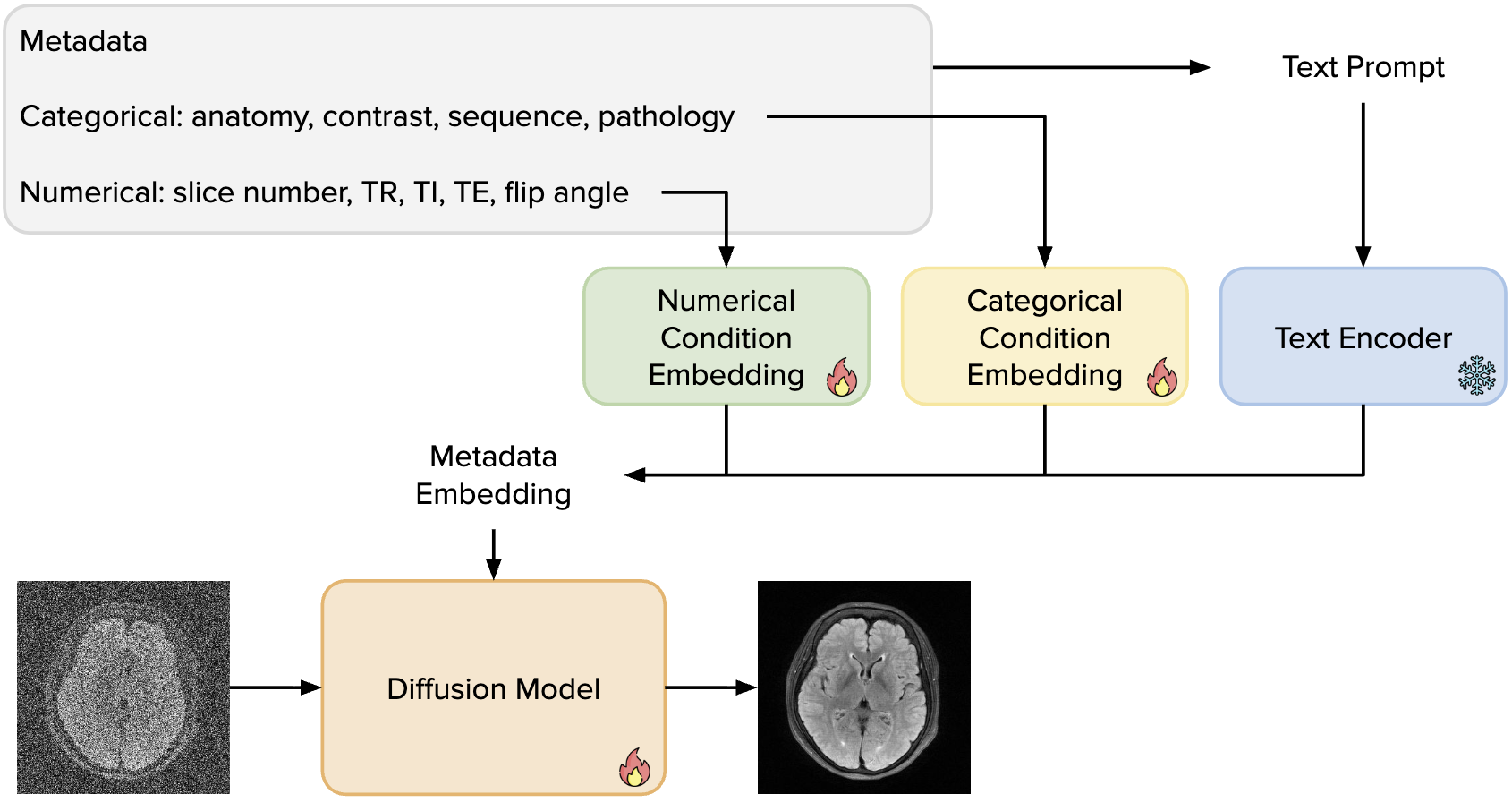
Metadata Matters: Diffusion-Based MRI Reconstruction with Metadata Conditioning
Developed a diffusion-based MRI reconstruction framework that leverages fine-grained metadata embeddings to adapt reconstruction across diverse acquisition settings. Designed a structured embedding architecture and introduced an out-of-distribution training strategy using cardiac MRI data to enhance generalization and interpretability on the fastMRI brain dataset.
Research in progress
Multi-Scale Diffusion Transformer for Stereo Depth Estimation
Building a diffusion-based hourglass transformer for disparity prediction on synthetic stereo datasets with polygonal objects, integrating geometric cues to improve boundary sharpness and spatial consistency.
Research in progress
Large-Scale Selfie Video Dataset (L-SVD): A Benchmark for Emotion Recognition
Curating and releasing a large-scale video dataset for facial emotion recognition and exploring text–image compositionality for structured perception and reasoning.
Dataset release
github page